My son fishes. Properly fishes. He knows which bait works at which tide, what the wind needs to be doing, when the flathead move from the flats into the channel. The kid has done his research. I know two knots. The Uni Knot and the Uni-to-Uni. That’s my entire repertoire.
We fish together sometimes, usually at Queens Wharf in Newcastle, where he sighs at my casting and re-ties my hooks without being asked. Through those afternoons I picked up something that stuck with me: fishing isn’t luck. It’s patterns. Tide, wind, swell, time of day, season, water temperature, what it rained last week. There’s a window when conditions line up, and if you miss it, you’re just sitting there holding a rod.
I’d just finished building the Google Search Console insights tool and I was thinking about the same idea in a different shape. That project was about extracting signal from data so someone could act instead of stare at a dashboard. Could I do the same thing for fishing conditions? Pull live weather, tides, and swell data from public APIs, score each spot based on what’s actually happening right now, and tell you whether it’s worth going?
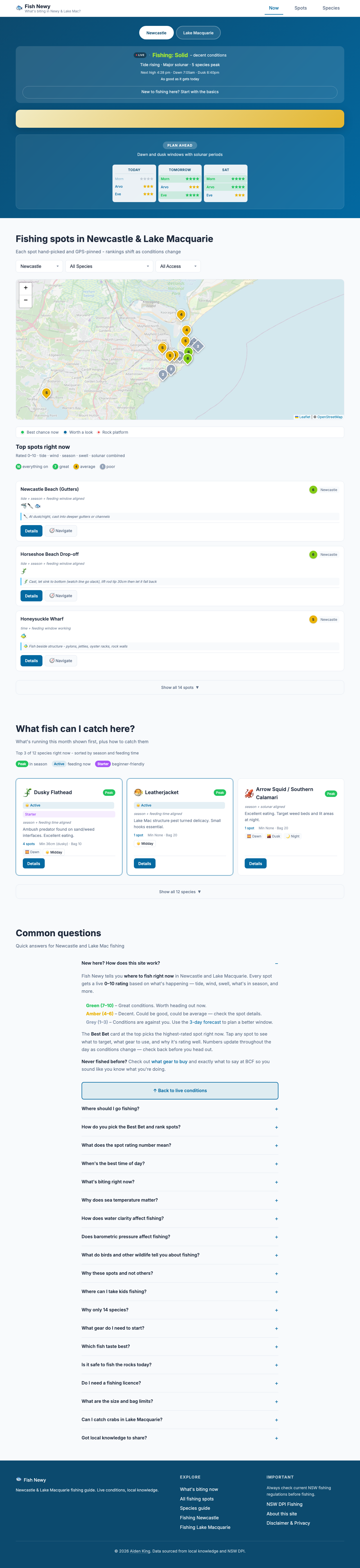
So I built Fish Newy. 31 spots across Newcastle and Lake Macquarie. 14 species with tackle recommendations and regulations. Live conditions updated from three free weather APIs. You open it, you see what’s biting, you go or you don’t.

The hidden experiment
Here’s the part I don’t talk about much. Fish Newy is also a laboratory.
I wanted to understand how a small, new, single-author website can get noticed. Not just by Google, but by the AI systems that are increasingly answering people’s questions before they ever click a link. ChatGPT, Perplexity, Claude, Google’s AI Overviews. When someone asks “where should I fish in Newcastle?”, who gets cited?
The answer, predictably, is government sites, established media, and Wikipedia. A fishing conditions app built by a German bloke in Lake Macquarie doesn’t naturally slot into that hierarchy. So I had to think about what actually drives AI citation and work it from the ground up.
What’s under the hood
Every page on Fish Newy is built to be readable by both humans and machines, but in different ways.
For search engines, each spot and species has its own URL with structured data, specifically JSON-LD schemas that tell Google exactly what the page is about, where it is geographically, what questions it answers. The homepage has 34 FAQ pairs, and 25 of them are dynamic: the server rewrites the answers with live data before the page is served. When Google crawls the FAQ “What fish are biting in Newcastle today?”, the answer includes today’s actual sea temperature, wind speed, tide state, and which species are in season this week.
For AI crawlers specifically, the site carries an llms.txt file, a structured summary that follows an emerging specification for making content digestible to language models. It includes local fishing slang (because someone searching for “jewies in Newy” needs to match “mulloway in Newcastle”), GPS coordinates for every spot, and specific tackle recommendations detailed enough to be cited directly. The robots.txt explicitly whitelists every known AI crawler by name: GPTBot, ClaudeBot, PerplexityBot, and eight others.
There’s also a speakable specification in the schema markup, telling voice assistants which parts of the page are suitable for reading aloud. And the entire FAQ schema is designed so that the questions match the way people actually ask. Conversational queries, not keyword strings.
Why this matters beyond fishing
Most businesses either block AI crawlers entirely or ignore them. The ones that think about it tend to stop at “we should probably have an llms.txt file” without understanding what actually drives citation.
The honest truth, which I’ve documented in detail for my own reference, is that most of the emerging “LLM optimisation” advice is theatre. Asking an LLM to cite you in your llms.txt file doesn’t work — models don’t follow instructions embedded in crawled content. What does work is specificity, structured data that matches real queries, and unique information that can’t be found anywhere else. GPS coordinates for 31 fishing spots with tide-specific advice is the kind of content that earns citation because no one else has it at that granularity.
I call this approach AgentReady: making your content discoverable not just by search engines but by the AI agents that are starting to answer questions on behalf of users. Fish Newy is where I test what works before recommending it to anyone else.
Set it and forget it
The whole thing runs on three free public APIs, a bit of PHP, and some JavaScript. No paid services, no subscriptions, no maintenance burden. The data updates itself. The scoring algorithms run server-side. I deploy with rsync to a shared hosting account and don’t think about it for weeks at a time.
Occasionally I come back and add something. A new species guide. A tweak to the water clarity estimation. Another FAQ question matched to a query I’ve seen in Search Console. But the core has been running unattended since I built it, which was always the point. If a tool needs constant feeding, it’s not a tool. It’s a pet.
I’ve since built a similar intelligence layer for property data in the same region. Different question, same approach: public data that nobody had assembled in one place, centred on the one location you actually care about.
The verdict
I showed my son the finished site. He poked around, checked a few spots, tested it against what he knows from years of actual fishing experience.
“It’s ok,” he said.
From a teenage son, that’s a five-star review. I’ll take it.